| GPT-1 |
June 2018 |
OpenAI |
0.117 |
|
1 |
MIT
|
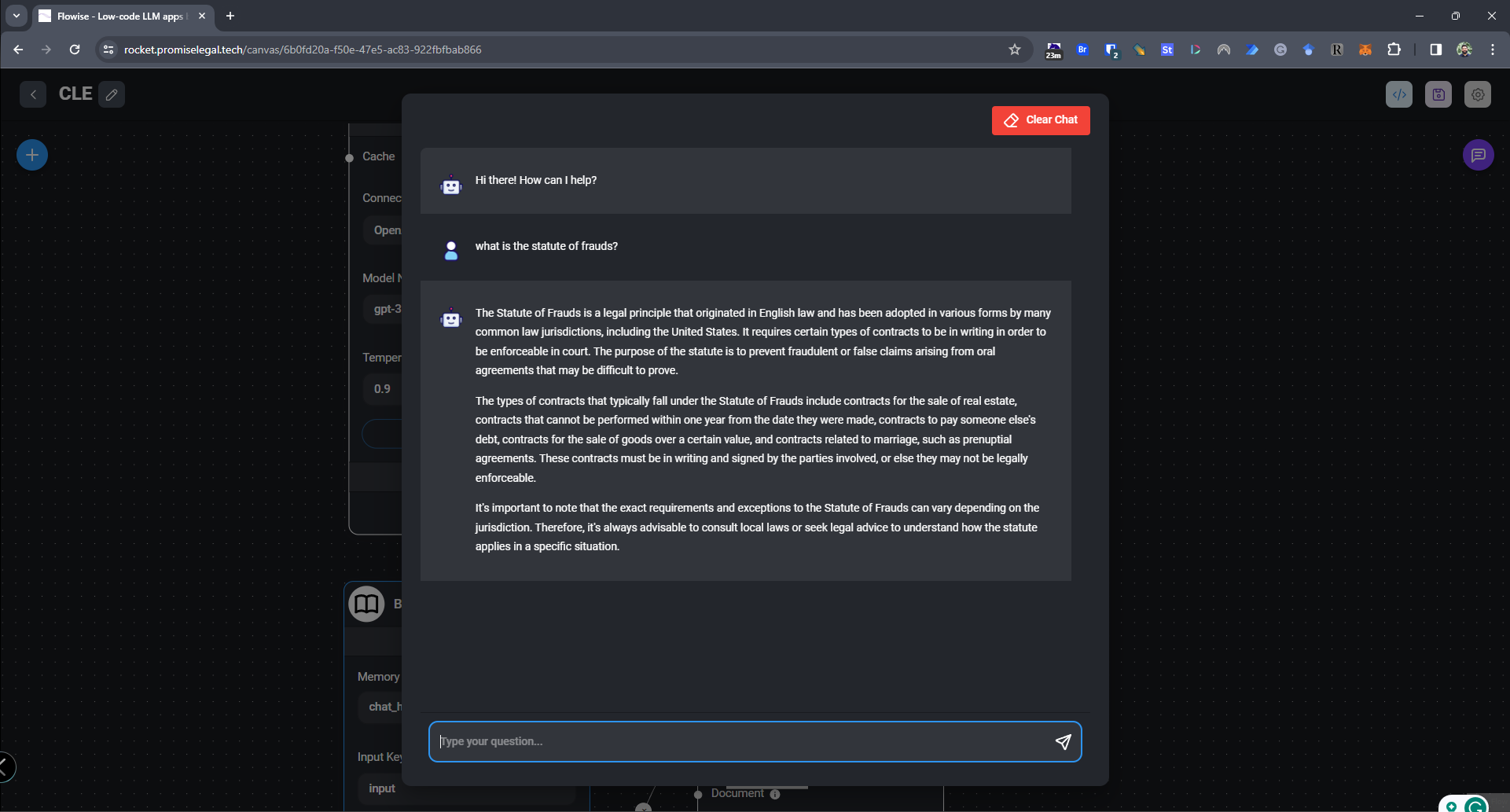
First GPT model, decoder-only transformer. Trained for 30 days on 8 P600 GPUs.
|
| BERT |
October 2018 |
Google |
0.340 |
3.3 billion words
|
9 |
Apache 2.0
|
An early and influential language model, but encoder-only and thus not built to be prompted or generative
|
| T5
|
October 2019
|
Google
|
11
|
34 billion tokens
|
|
Apache 2.0
|
Base model for many Google projects, such as Imagen.
|
| XLNet |
June 2019 |
Google |
~0.340 |
33 billion words
|
|
Apache 2.0
|
An alternative to BERT; designed as encoder-only
|
| GPT-2 |
February 2019 |
OpenAI |
1.5 |
40GB (~10 billion tokens)
|
28 |
MIT
|
Trained on 32 TPUv3 chips for 1 week.
|
| GPT-3 |
May 2020 |
OpenAI |
175 |
300 billion tokens
|
3640 |
proprietary
|
A fine-tuned variant of GPT-3, termed GPT-3.5, was made available to the public through a web interface called ChatGPT in 2022.
|
| GPT-Neo |
March 2021 |
EleutherAI |
2.7 |
825 GiB
|
|
MIT
|
The first of a series of free GPT-3 alternatives released by EleutherAI. GPT-Neo outperformed an equivalent-size GPT-3 model on some benchmarks, but was significantly worse than the largest GPT-3.
|
| GPT-J |
June 2021 |
EleutherAI |
6 |
825 GiB
|
200 |
Apache 2.0
|
GPT-3-style language model
|
| Megatron-Turing NLG |
October 2021 |
Microsoft and Nvidia |
530 |
338.6 billion tokens
|
|
Restricted web access
|
Standard architecture but trained on a supercomputing cluster.
|
| Ernie 3.0 Titan |
December 2021 |
Baidu |
260 |
4 Tb
|
|
Proprietary
|
Chinese-language LLM. Ernie Bot is based on this model.
|
| Claude |
December 2021 |
Anthropic |
52 |
400 billion tokens
|
|
beta
|
Fine-tuned for desirable behavior in conversations.
|
| GLaM (Generalist Language Model) |
December 2021 |
Google |
1200 |
1.6 trillion tokens
|
5600 |
Proprietary
|
Sparse mixture of experts model, making it more expensive to train but cheaper to run inference compared to GPT-3.
|
| Gopher |
December 2021 |
DeepMind |
280 |
300 billion tokens
|
5833 |
Proprietary
|
Later developed into the Chinchilla model.
|
| LaMDA (Language Models for Dialog Applications) |
January 2022 |
Google |
137 |
1.56T words, 168 billion tokens
|
4110 |
Proprietary
|
Specialized for response generation in conversations.
|
| GPT-NeoX |
February 2022 |
EleutherAI |
20 |
825 GiB
|
740 |
Apache 2.0
|
based on the Megatron architecture
|
| Chinchilla |
March 2022 |
DeepMind |
70 |
1.4 trillion tokens
|
6805 |
Proprietary
|
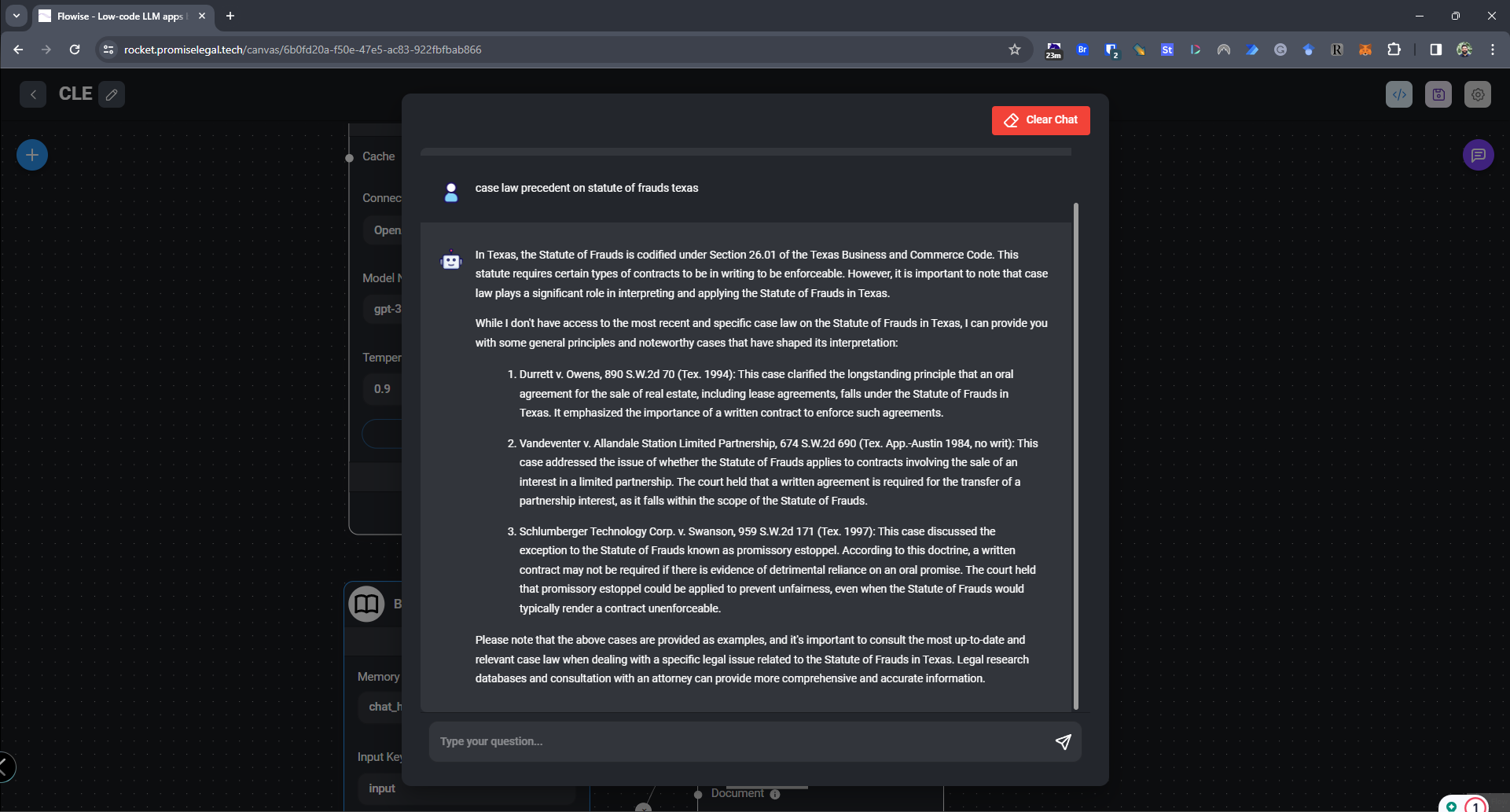
Reduced-parameter model trained on more data. Used in the Sparrow bot. Often cited for its neural scaling law.
|
| PaLM (Pathways Language Model) |
April 2022 |
Google |
540 |
768 billion tokens
|
29250 |
Proprietary
|
Trained for ~60 days on ~6000 TPU v4 chips.
|
| OPT (Open Pretrained Transformer) |
May 2022 |
Meta |
175 |
180 billion tokens
|
310 |
Non-commercial research
|
GPT-3 architecture with some adaptations from Megatron
|
| YaLM 100B |
June 2022 |
Yandex |
100
|
1.7TB |
|
Apache 2.0 |
English-Russian model based on Microsoft's Megatron-LM.
|
| Minerva |
June 2022 |
Google |
540 |
38.5B tokens from webpages filtered for mathematical content and from papers submitted to the arXiv preprint server
|
|
Proprietary
|
For solving "mathematical and scientific questions using step-by-step reasoning". Based on PaLM model, further trained on mathematical and scientific data.
|
| BLOOM |
July 2022 |
Large collaboration led by Hugging Face |
175 |
350 billion tokens (1.6TB)
|
|
Responsible AI
|
Essentially GPT-3 but trained on a multi-lingual corpus (30% English excluding programming languages)
|
| Galactica |
November 2022 |
Meta |
120 |
106 billion tokens
|
unknown |
CC-BY-NC-4.0
|
Trained on scientific text and modalities.
|
| AlexaTM (Teacher Models) |
November 2022 |
Amazon |
20 |
1.3 trillion
|
|
proprietary
|
bidirectional sequence-to-sequence architecture
|
| Neuro-sama |
December 2022 |
Independent |
Unknown |
Unknown
|
|
privately-owned
|
A language model designed for live-streaming on Twitch.
|
| LLaMA (Large Language Model Meta AI) |
February 2023 |
Meta AI |
65 |
1.4 trillion
|
6300 |
Non-commercial research
|
Corpus has 20 languages. "Overtrained" (compared to Chinchilla scaling law) for better performance with fewer parameters.
|
| GPT-4 |
March 2023 |
OpenAI |
Unknown |
Unknown
|
Unknown |
proprietary
|
Available for ChatGPT Plus users and used in several products.
|
| Cerebras-GPT
|
March 2023
|
Cerebras
|
13
|
|
270 |
Apache 2.0
|
Trained with Chinchilla formula.
|
| Falcon |
March 2023 |
Technology Innovation Institute |
40 |
1 trillion tokens, from RefinedWeb (filtered web text corpus) plus some "curated corpora".
|
2800 |
Apache 2.0
|
|
| BloombergGPT |
March 2023 |
Bloomberg L.P. |
50 |
363 billion token dataset based on Bloomberg's data sources, plus 345 billion tokens from general purpose datasets
|
|
Proprietary
|
Trained on financial data from proprietary sources, for financial tasks.
|
| PanGu-Σ |
March 2023 |
Huawei |
1085 |
329 billion tokens
|
|
Proprietary
|
|
| OpenAssistant |
March 2023 |
LAION |
17 |
1.5 trillion tokens
|
|
Apache 2.0
|
Trained on crowdsourced open data
|
| Jurassic-2
|
March 2023
|
AI21 Labs
|
Unknown
|
Unknown
|
|
Proprietary
|
Multilingual
|
| PaLM 2 (Pathways Language Model 2) |
May 2023 |
Google |
340 |
3.6 trillion tokens
|
85000 |
Proprietary
|
Was used in Bard chatbot.
|
| Llama 2 |
July 2023 |
Meta AI |
70 |
2 trillion tokens
|
21000 |
Llama 2 license
|
1.7 million A100-hours.
|
| Claude 2
|
July 2023
|
Anthropic
|
Unknown
|
Unknown
|
Unknown |
Proprietary
|
Used in Claude chatbot.
|
| Mistral 7B |
September 2023 |
Mistral AI |
7.3 |
Unknown
|
|
Apache 2.0
|
|
| Claude 2.1
|
November 2023
|
Anthropic
|
Unknown
|
Unknown
|
Unknown |
Proprietary
|
Used in Claude chatbot. Has a context window of 200,000 tokens, or ~500 pages.
|
| Grok-1
|
November 2023
|
x.AI
|
314
|
Unknown
|
Unknown |
Apache 2.0
|
Used in Grok chatbot. Grok-1 has a context length of 8,192 tokens and has access to X (Twitter).
|
| Gemini 1.0
|
December 2023
|
Google DeepMind
|
Unknown
|
Unknown
|
Unknown |
Proprietary
|
Multimodal model, comes in three sizes. Used in the chatbot of the same name.
|
| Mixtral 8x7B
|
December 2023
|
Mistral AI
|
46.7
|
Unknown
|
Unknown |
Apache 2.0
|
Outperforms GPT-3.5 and Llama 2 70B on many benchmarks. Mixture of experts model, with 12.9 billion parameters activated per token.
|
| Mixtral 8x22B
|
April 2024
|
Mistral AI
|
141
|
Unknown
|
Unknown |
Apache 2.0
|
|
| Phi-2
|
December 2023
|
Microsoft
|
2.7
|
1.4T tokens
|
419 |
MIT
|
Trained on real and synthetic "textbook-quality" data, for 14 days on 96 A100 GPUs.
|
| Gemini 1.5
|
February 2024
|
Google DeepMind
|
Unknown
|
Unknown
|
Unknown |
Proprietary
|
Multimodal model, based on a Mixture-of-Experts (MoE) architecture. Context window above 1 million tokens.
|
| Gemma |
February 2024 |
Google DeepMind |
7 |
6T tokens |
Unknown |
Gemma Terms of Use |
|
| Claude 3
|
March 2024
|
Anthropic
|
Unknown
|
Unknown
|
Unknown
|
Proprietary
|
Includes three models, Haiku, Sonnet, and Opus.
|
| DBRX
|
March 2024
|
Databricks and Mosaic ML
|
136
|
12T Tokens
|
|
Databricks Open Model License
|
Training cost 10 million USD.
|
| Fugaku-LLM
|
May 2024
|
Fujitsu, Tokyo Institute of Technology, etc.
|
13
|
380B Tokens
|
|
|
The largest model ever trained on CPU-only, on the Fugaku.
|
| Phi-3
|
April 2024
|
Microsoft
|
14
|
4.8T Tokens
|
|
MIT
|
Microsoft markets them as "small language model".
|
| Qwen2
|
June 2024
|
Alibaba Cloud
|
72
|
3T Tokens
|
|
|
Multiple sizes, the smallest being 0.5B.
|
| Nemotron-4
|
June 2024
|
Nvidia
|
340
|
9T Tokens
|
200,000
|
NVIDIA Open Model License
|
Trained for 1 epoch. Trained on 6144 H100 GPUs between December 2023 and May 2024.
|
| Llama 3.1
|
July 2024
|
Meta AI
|
405
|
15.6T tokens
|
440,000
|
Llama 3 license
|
405B version took 31 million hours on H100-80GB, at 3.8E25 FLOPs.
|